Для тех, кто связан созданием сайтов, дропами, сетками сайтов и тому подобное не нужно объяснять, как полезен сайт web.archive.org (веб архив орг).
Основная его задача посмотреть web архив сайтов которых уже нет в поисковой выдаче. Т.е. контент сайта и его структура, который был размещен на нем ранее. Конечно, архив есть не для всех сайтов. В основном для активных сайтов, которые развивались.
Как посмотреть архив сайта
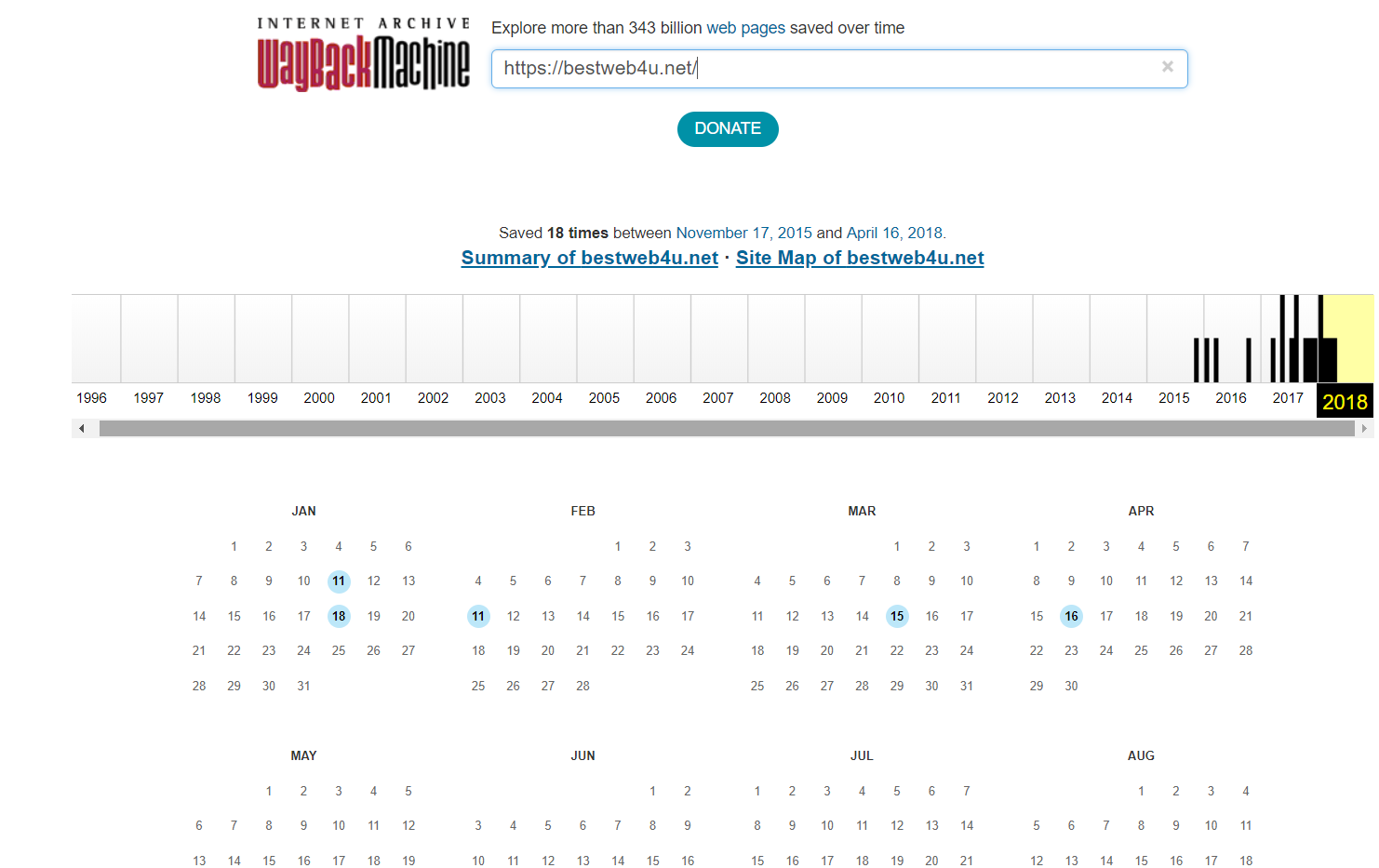
Все просто, открываем сайт http://web.archive.org/ и вводим нужный сайт в строку поиска.
Далее, если у сайта есть архив, Вы увидите даты, в виде календаря, за которые имеются архивы. Нужно просто выбрать дату, для открытия сайта.
Еще можно проверить архив сайта сразу написав в адресной строке браузера
https://web.archive.org/web/*/ + нужный сайт, например
https://web.archive.org/web/*/https://bestweb4u.net/
Рассмотрим случай, когда Вы хотите купить домен, не новый, но который уже закончился, но скажем у него уже есть ссылочная масса, ИКС и другие показатели. Такой сайт будет проще продвинуть. А еще лучше будет восстановить его структуру и контент. В таком случае поисковики быстро обойдут его, и все восстановят. И Вы начнете получать трафик. Понятно, что это очень идеальный вариант.
Именно в этом случае Вам поможет Веб Архив. Найти такой домен тяжело, и нужно чтобы еще и архив был. Зачастую приходится проверить много сайтов на доступность архива.
Парсер веб архива (web.archive.org)
У меня недавно была такая нужда. И так как я пользуюсь универсальным парсером Datacol, то без труда набросал проект, который поможет в этом.
Это готовый проект парсер/чекер web.archive.org под Датакол. Парсер веб архива проверяет каждый сайт и находит дату первого архива, дату последнего архива и отдельно параметр есть сайт в архиве или нет. Хотя если есть даты, то и так понятно, что сайт есть в архиве. Для проверки нужно всего лишь подготовить список сайтов или доменов. На выходе получите CSV файл с данными по каждому сайту.
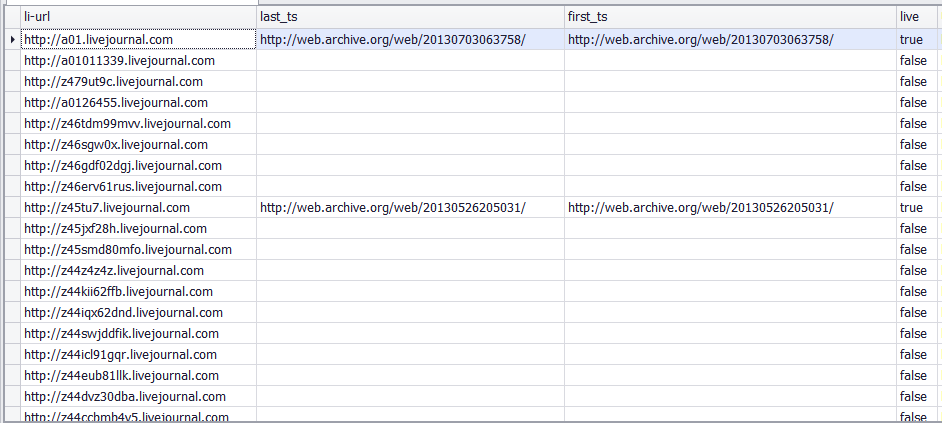
Парсер web.archive.org абсолютно бесплатный и скачать его может каждый. Настройка очень проста. Просто задаете список доменов/сайтов в список начальных URL и в экспорте задаете папку для сохранение итогового файла. По умолчанию в корень диска D.
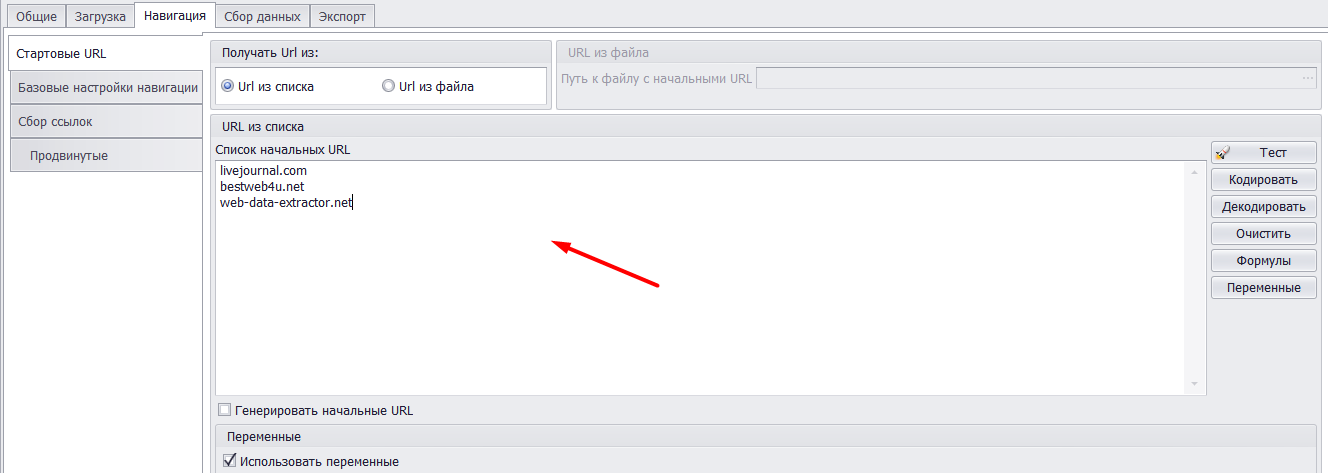
Для тех, кто не знаком с Датакол, можно ознакомится с возможностями на офф сайте. И также получить скидку 20% на его покупку.
Если Вам нужна доработка парсера под свои нужды, пишите в форму ниже.

