
Для многих это, как оказалось, очень сложная тема и темный лес ) Многие их боятся. Но стоит попробовать их использовать и через некоторое время Вы их полюбите.
И все же перед дальнейшей практикой настоятельно рекомендую прочитать теорию в справке Датакол: теория, часто используемые выражения.
Ну и теперь перейдем к полезностям и советам/рекомендациям по регуляркам:
У регулярных выражений есть метасимволы
. ^ $ * + ? { } [ ] \ | ( )
Если в Вашем выражении есть какието из этих символов, то его обязательно нужно "экранировать", т.е ставить слеш "\" перед ним. Например есть выражение в скобках "(сегодня)" регулярка для него будет
\(сегодня\)
Также в регулярках есть заранее предопределенные наборы символов:
- \d - любая цифра или можно так [0-9]
- \D - наоборот, НЕ цифра или можно так [^0-9]
- \s - любой символ whitespace или можно так [ \t\n\r\f\v]
- \S - наоборот, НЕ whitespace символу или [^ \t\n\r\f\v]
- \w - любая буква (латинская), цифра или _ аналогично [a-zA-Z0-9_]
- \W - наоборот, эквивалент [^a-zA-Z0-9_]
Чтобы явно указать, сколько раз должен повторится символ, нужно указать в фигурных скобках количество {1}, также можно указать диапазон {1,5} или {2,} т.е от 2-х до бесконечности.
Также важный момент, в регулярных выражениях есть группы совпадения. Взяв в скобки (без экранирования) выражение вы можете обратиться к нему по порядковому номеру.
Теперь перейдем к примеру. Скажем у Вас есть строка с датой 27.03.2017. Составим регулярку:
([\d]{2})\.([\d]{2}).([\d]{4})
Разберем ее:
[\d]{2} - указываем что нужно найти 2 цифры
[\d]{4} - указываем что нужно найти 4 цифры
Также каждое выражение мы взяли в скобки (группу). У нас вышло 3 группы. Теперь указав номер группы в настройках строки вырезания, вы можете без дополнительной чистки получить то значение, которое нужно

В данном примере мы получим день, т.е число 27 из нашего примера. Если укажем 2 группу, то получим месяц, т.е 03 и соответственно 3-я группа это год - 2017.
Еще одна фишка, которой мало кто пользуется. Группы можно использовать в заменах! Оставим этот же пример с датой 27.03.2017. Например нам нужно переделать дату в формат месяц, день, год и сделать расделителем дефис "-" 03-27-2017. У нас есть наше выражение
([\d]{2})\.([\d]{2}).([\d]{4})
И мы в заменах делаем замену на $2-$1-$3 и получаем
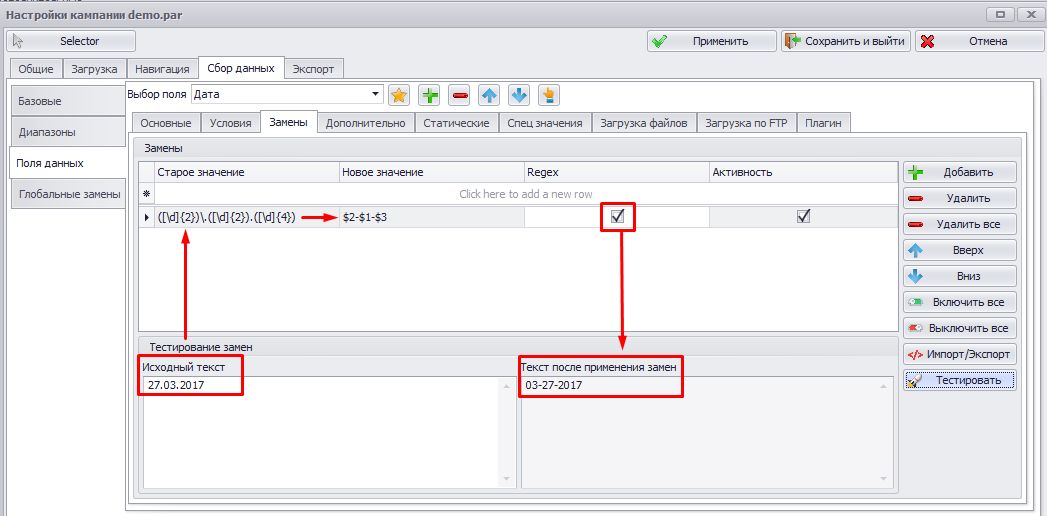
Т.е в заменах группа обозначается символом "$". Вы можете делать и другие преобразования, какие Вам нужно.
Одна из регулярок (regexp) которая поможет найти E-mail
[a-z0-9_\.-]+@[a-z0-9_-]+\.[a-zA-Z]{2,6}
Находим заголовок документа (title)
<title>([^<>]*?)</title>
При поиске в тегах/между тегами рекомендую использовать выражение [^<>]*? вместо .*? . Это при сложных запросах ускорит поиск и вы точно найдете то, что нужно. Т.к в этом случае идет поиск исключая "<" и ">", т.е вы в любом случае не выйдите за рамки тега.
Находим метатег дескрипшен (description)
<meta name="description" content="([^<>]*?)">
Также рекомендую для кавычек использовать ['"] т.е либо одинарная либо двойная. Т.к в коде может быть по разному и еще вы можете включить стандартные замены, а в них двойная кавычка заменяется одинарной. И что бы сразу избежать подобных трудностей, переделаем регулярку
<meta name=['"]description['"] content=['"]([^<>]*?)['"]>
Находим метатег кейвордс (keywords)
<meta name=['"]keywords['"] content=['"]([^<>]*?)['"]>
Продолжение статьи >>>

[^]*? или может нужна точка перед звездочкой [^].*? бо вроде как без точки не работает
Вы для начала почитайте теорию.
.*? - любая строка (. - любой символ ; * - любое количество раз; ? - выбираем самое короткое совпадение из всех возможных)
То что вы указали в скобках не понятно зачем.
^ - это метасимвол начала строки